
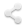
")
Post by Ambika Vyas, undergraduate in Computer Science with a minor in Interdisciplinary Neuroscience at Portland State University. Ambika is working under Dr. Suresh Singh as part of her undergraduate thesis studying machine learning techniques used in mental health research.

One of the main reasons I chose a computer science degree was its versatility.
I already knew those with programming skills who brought their talents to a wide variety of companies— IBM, John Hopkin’s, and even Disney. After my internship at OHSU’s DICE (Division of Informatics, Clinical Epidemiology and Translational Data Science), I realized I wanted to contribute to computer science research, specifically in health and biomedical informatics.
Translational data science is the bridge between raw data analysis and practical, real-world applications. In other words, analyzing raw data can potentially “translate” into something useful and important. Biomedical informatics is the study of healthcare information and how this data might lead to improvements in healthcare and public health.
I complemented my computer science degree with a minor in interdisciplinary neuroscience to get a more significant clinical perspective and to be able to write my thesis on something relating to mental health, which I knew I wanted to do for a while.
LEARN MORE: About Translational Science
LEARN MORE: Principles of Translational Science
LEARN MORE: OHSU– What is Biomedical Informatics?
LEARN MORE: National Center for Advancing Translational Sciences
LEARN MORE: Interdisciplinary Neuroscience Minor
This year-long experience of taking honors writing classes and a neuroscience class gave me the skills to articulate my research in a more accessible and understandable manner. These are important skills for someone who has been immersed in highly technical jargon for a couple of years in my degree!

LEARN MORE: OHSU College Undergraduate and Graduate Biomedical Informatics and Data Science Internship Program
Finding a lab
It’s not always easy to find a mentor in college. I searched for a faculty mentor from July to September of 2025.
It took many, many emails, but Dr. Suresh Singh, a computer science professor and researcher in machine learning, high-speed wireless communication, and sensing, replied and we set up an interview. He was willing to be my faculty mentor, and during our first few meetings we went over what machine learning research I was interested in and how I wanted to pursue my thesis.
Through discussions with Dr. Singh, I developed a better understanding of which topics might be best to study.
For example, I decided to focus on deeply researched mental health disorders with more evidence to pinpoint abnormalities, including depression and autism. Singh noted that chatbot therapy, which involves direct interactions between a human and an AI system, has significant risks in clinical applications. I decided that I did not want to fixate on it in my thesis due to these known risks and availability of other rigorously tested therapeutic methods. Methods mentioned in my thesis do not involve direct interactions between patients and chatbot or other ML/AI systems; rather, I’m more interested in diagnostic tools.
LEARN MORE: Potentially Harmful Consequences of AI Chatbot Use Among Patients With Mental Illness
LEARN MORE: Their teenage sons died by suicide. Now, they are sounding an alarm about AI chatbots
LEARN MORE: Use of generative AI chatbots and wellness applications for mental health (APA)
LEARN MORE: A Systematic Review on Mental Health Chatbots
In the first few meetings, I would often put my thoughts into a PowerPoint, present them, and receive feedback before actually getting to my thesis. I became particularly interested in what’s called the “explanatory gap” – how we struggle to explain why some physical, biological processes in the brain are accompanied by subjective, conscious feelings. I’m especially curious about the subjective experiences of depression and anxiety, and what we might learn about the underlying physiological states that lead there. Might machine learning tools help predict subjective outcomes?

This PowerPoint slide (above) represents some of my initial ideas.
The final focus of my research is on computational tools that can be used to resolve the explanatory gap, but this draft of my plan a couple months back mentioned concepts and articles that I incorporated into the final thesis. Molecular changes in the brain, for example, were certainly a focus, but I’m now looking at how neural networks might track and predict these changes.
LEARN MORE: Computational psychiatry
LEARN MORE: Understanding mental health through computers
LEARN MORE: Toward Psychoinformatics: Computer Science Meets Psychology
LEARN MORE: Translational Digital and Computational Psychiatry Program (NIMH)
LEARN MORE: AI’s a suck up. Research shows how it flatters and suggests we’re not to blame
LEARN MORE: Promoting psychology in NIH’s Strategic Plan on Data Science
Dr. Singh works with Natural Language Processing (NLP), which is a branch of Artificial Intelligence that allows computers to understand human language through a combination of language inputs (many from the internet), statistical modeling, and machine learning. Generative AI is the direct result of NLP.
It is important to note that machine learning and artificial intelligence are distinct fields. Computer scientists often disagree on whether artificial intelligence is part of machine learning, if machine learning is part of artificial intelligence, or if neither is true. Personally, I consider AI an application of machine learning. A practical example are sensors that supply data to models trained with machine learning. However, some adaptive (live data and feedback loops) AI-systems are not based on machine learning.
LEARN MORE: AI vs. machine learning vs. deep learning vs. neural networks: What’s the difference?
LEARN MORE: AI and Machine Learning: What to know and how to talk about it to researchers and patrons
LEARN MORE: Adaptive AI Agent Systems for Personalized Learning
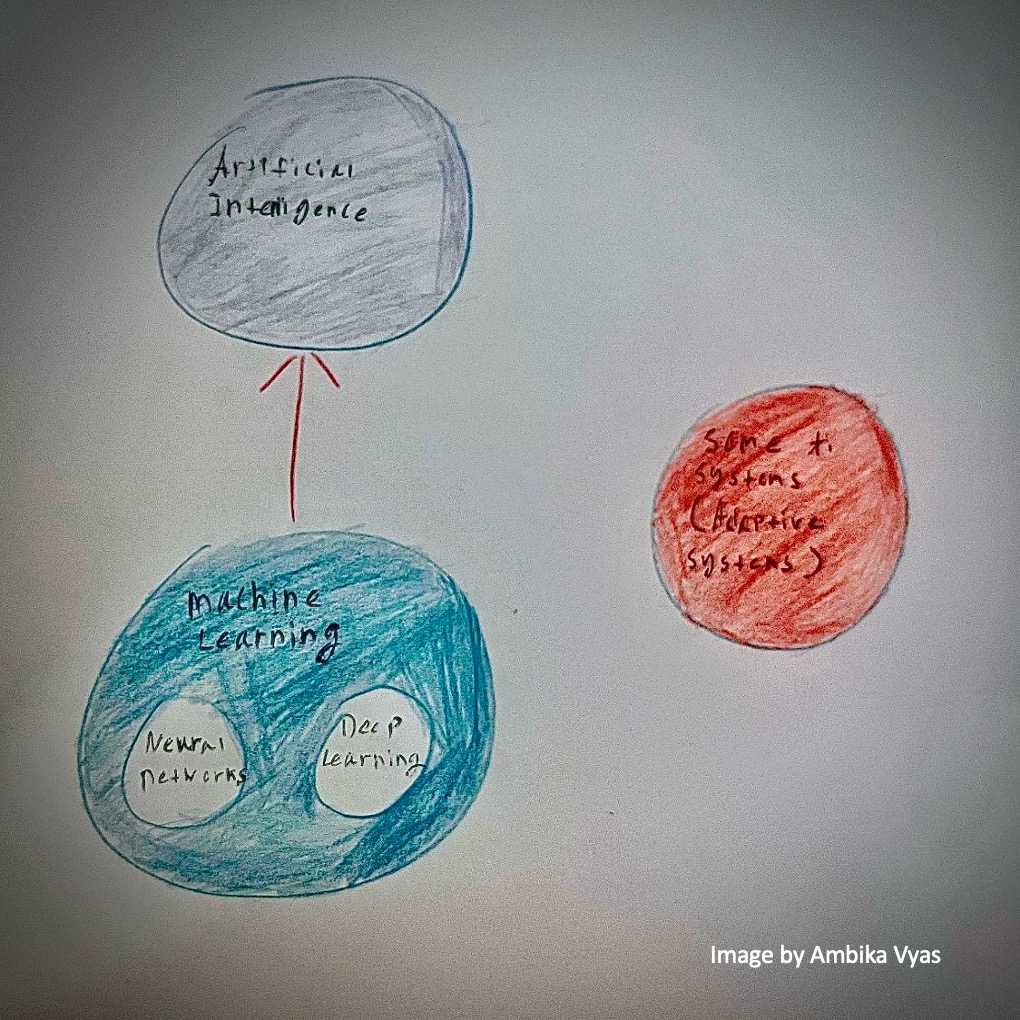
The applications of machine learning that our lab deals with are vast, from traffic merging for mitigating the electricity consumption of data centers (traffic merging refers to traffic from data centers being combined to prevent them from operating at maximum load) to waste classification (is this item recyclable or not?).
While the significant resources that data centers take up to support AI are clearly problematic, some of Singh’s work relates to improving this network architecture. His research seeks to strike a balance between reducing energy in data centers and preventing “packet loss,” where critical units of data cannot reach their destination. In traffic merging, more specifically low-traffic merging, small traffic streams are grouped together from many links, and unused ports are kept in low-power. This can save energy as opposed to leaving switch ports on at full speed when doing so is not justified by the low level of activity.
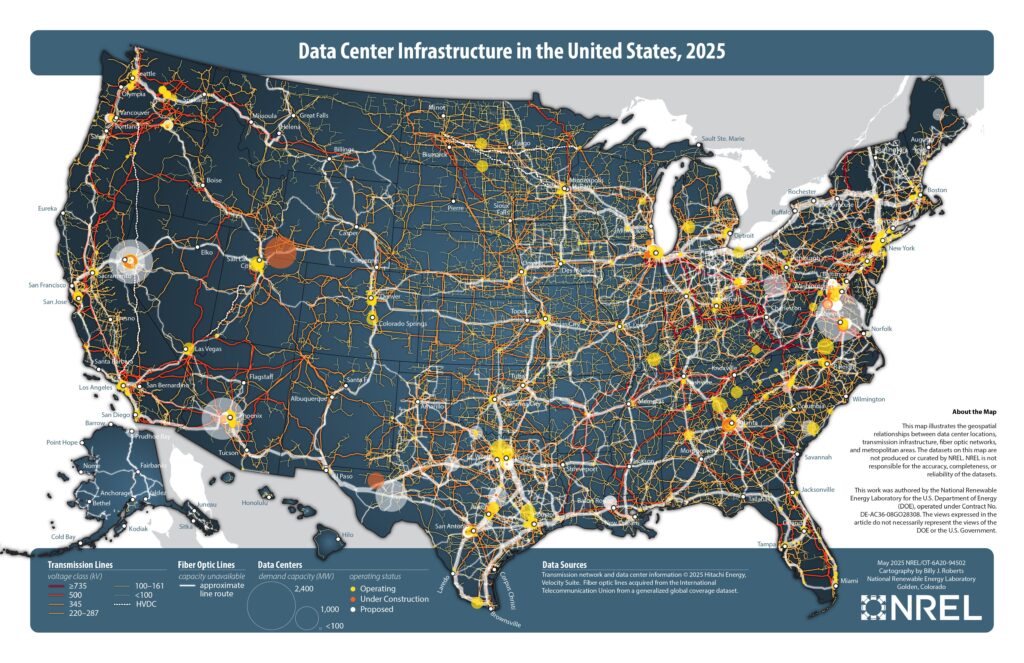
IMAGE SOURCE: NREL launches US data center infrastructure map
LEARN MORE: What we know about energy use at U.S. data centers amid the AI boom
LEARN MORE: Data Center Energy Needs Could Upend Power Grids and Threaten the Climate
LEARN MORE: Review of energy efficiency and technological advancements in data center power systems
LEARN MORE: Portland General Electric’s data center customers to pay more for electricity under landmark law
Another recent paper published by the Singh lab focused on fuzzy reasoning, where Large Language Models (LLMs) attempt to come to conclusions that aren’t necessarily true or false — rather, there are degrees of truth in a “false” conclusion.
LEARN MORE: What is NLP?
LEARN MORE: An introduction to Deep Learning in Natural Language Processing
LEARN MORE: Are Large Language Models Good At Fuzzy Reasoning?
LEARN MORE: Fuzzy Reasoning
LEARN MORE: Recycling Dataset
However, I’m not focusing on these studies, since I’m not contributing anything directly relating to these lab projects. The primary goal for this experience was to receive mentorship on machine learning concepts as an undergraduate that I was not familiar with, and to apply these to observations from a comprehensive review of the existing research literature.
Starting my thesis
Again, I was interested in working on both machine learning and mental health/ neuroscience, but I wasn’t sure where to start. Dr. Singh suggested beginning with a broad problem (e.g., a specific mental health condition), issues with diagnosis/ treatment and the underlying physiological mechanisms that researchers have identified. My initial research found significant overlap between depression, anxiety, schizophrenia, and autism in the context of neural abnormalities and abnormal neural firing.
For example, the brain’s Excitation–Inhibition (E/I) imbalance, which involves differences in excitatory and inhibitory neurotransmitters, is linked to abnormal firing of neurons. Glutamate and GABA are excitatory and inhibitory neurotransmitters, respectfully. The seesaw of glutamate’s abnormally high or low relative presence has been attributed to the psychiatric disorders I mentioned, including the negative thought loops in depression and sensory overload in autism.
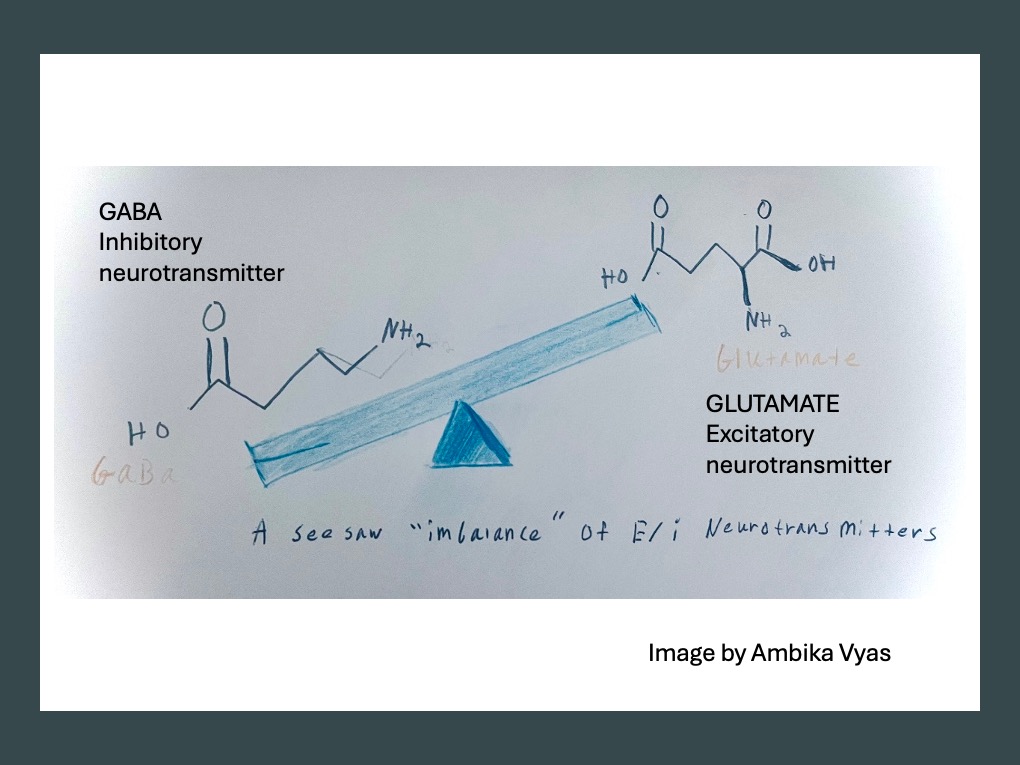
LEARN MORE: Computational neuroscience approach to biomarkers and treatments for mental disorders
LEARN MORE: Charting brain GABA and glutamate levels across psychiatric disorders
I decided to focus on depression and anxiety, due to how common and impactful these diagnoses are.
In 2020 – 2021, major depressive episodes occurred at rates of 7.1% in U.S. adults. Clinically diagnosed depression was 5.7%. Globally, 332 million people were diagnosed with depression. Treatment-resistant depression contributes a significant percentage (47.2%) of the economic burden of depression. Around 19.1% of U.S. adults have an anxiety disorder, and 31.1% of U.S. adults have had an anxiety disorder at any given point in their life. DALY (Disability-Adjusted Life Year) rates of anxiety are similar to depression, with an age-standardized rate of 360.12 (range of 248.60–494.44) per 100,000 people.
For depression, existing treatments, including medications, are not always effective. This is due to the lack of understanding of what causes specific symptoms of depression (e.g. anhedonia, rumination); rather, clinicians prescribe medications that work at specific receptors, but the multiple layers between receptors and behavioral changes aren’t necessarily understood.
LEARN MORE: Depression (NIMH)
LEARN MORE: Estimation of the Global Disease Burden of Depression and Anxiety
This is a key concept in my thesis which is called the explanatory gap.
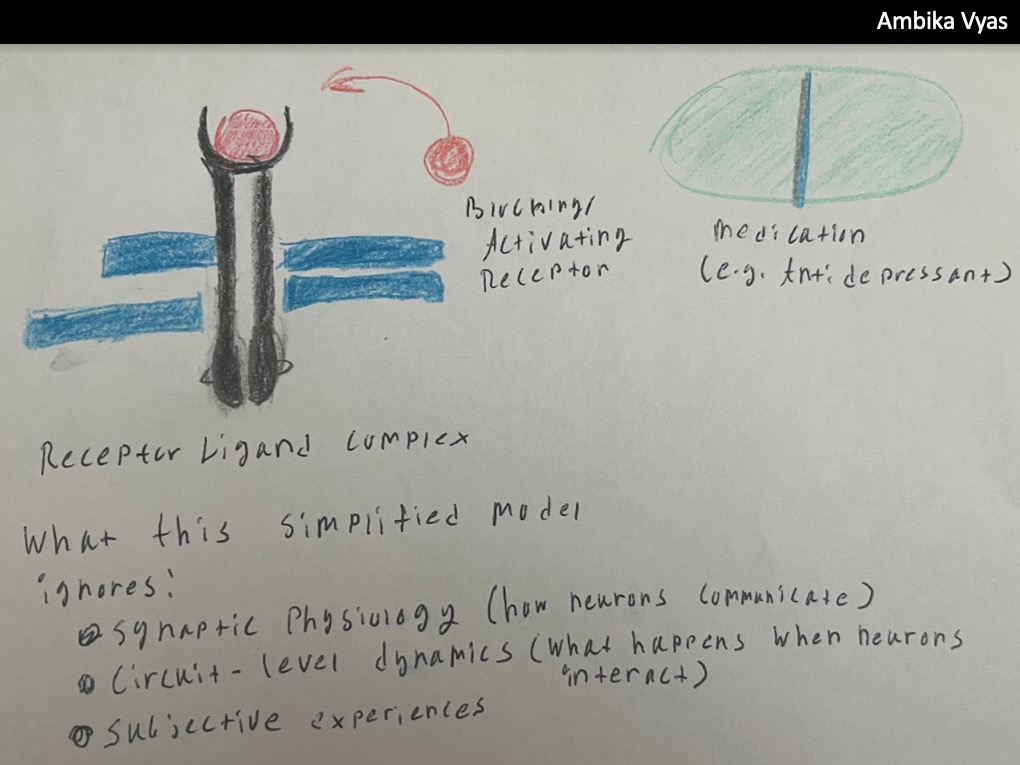
The explanatory gap is defined as the inability to explain phenomenal experiences from the standpoint of neural mechanisms. It is a widely discussed concept in scientific and philosophical literature. In neuroscience, the solution to the explanatory gap is highly sought out, but some suggest it is unsolvable. However, other scientists and academics argue it can be solved through traditional methods of scientific reasoning.
In general, knowledge of human cognition is not sufficient to prevent the explanatory gap. However, Michael Pauen, a philosopher from Humboldt University, Berlin, in 2025 proposed the representation of phenomenal experiences through functional terms. For example, a neurological sensation of pain is framed as the desire to avoid that pain. Pauen theorizes that the focus on these components increases the chance of being able to link qualitative experiences with scientifically tractable mechanisms.
LEARN MORE: The Explanatory Gap
LEARN MORE: A plank across the explanatory gap: The case of pain
LEARN MORE: Ligand-receptor interaction
{kind=link}
Can machine learning tools help bridge the explanatory gap?
My thesis is focused on machine learning tools that can bridge the explanatory gap in depression and anxiety.
Computer scientists have contributed to the development of tools that neuroscientists can use to further brain research, and potentially address the explanatory gap. Many tools are based on machine learning models, which can map out biochemical processes of the brain.
I grouped these tools into three broad categories: machine learning algorithms or networks, artificial intelligence applications, and bioinformatic tools. Of course, existing technologies are far more complex than this, but this classification identifies research fields that can provide objective solutions. During the developments of machine learning, many sub-fields and concepts have emerged that are specific to biomedical applications.
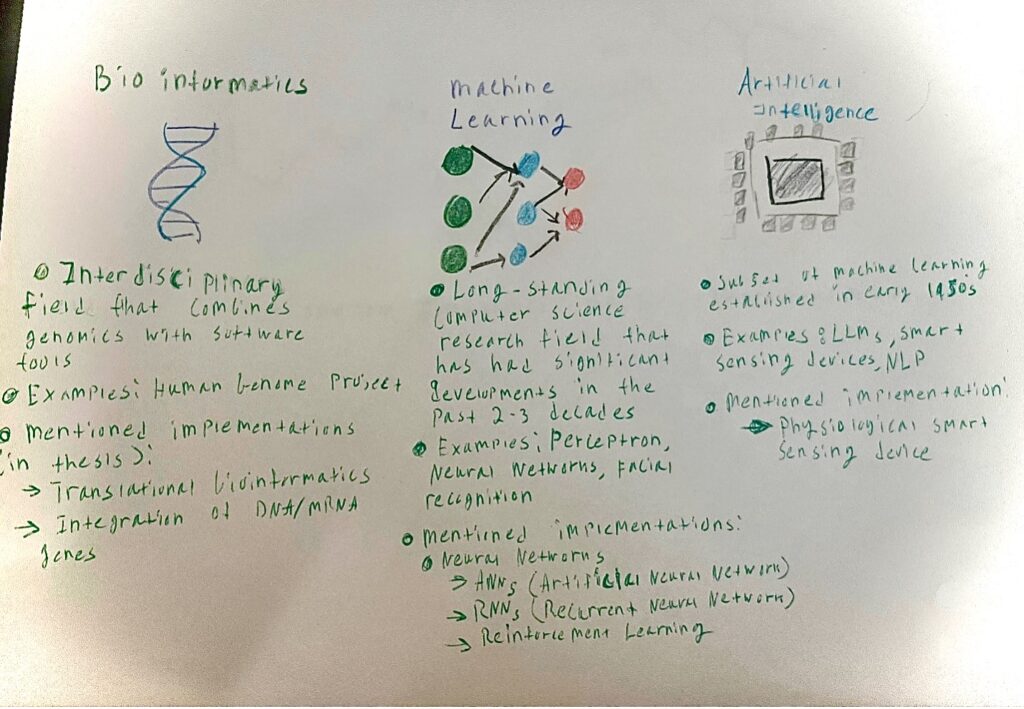
Neural networks, for example, are based on biology where artificial neurons are “stacked” on top of each other.
Variations of neural networks can be used depending on the clinical context (e.g. Recurrent Neural Networks for sequential data and Deep Neural Networks for drug design). Reinforcement learning, another machine learning technique, can link actions to behavior through a theory-driven approach.
Applied in research, these tools can potentially provide quantitative descriptions of specific neurological processes.
LEARN MORE: What is a neural network?
LEARN MORE: Analysis of hidden units in a layered network trained to classify sonar targets
LEARN MORE: Recurrent Neural Networks: A Comprehensive Review of Architectures, Variants, and Applications
LEARN MORE: Advances and Perspectives in Applying Deep Learning for Drug Design and Discovery
When it comes to AI applications, my primary focus was on sensors that use algorithms to predict a patient’s mental state; specifically, whether these patients are subjectively experiencing a state of stress or not.
LEARN MORE: Medically-oriented design for explainable AI for stress prediction from physiological measurements
Researchers use physiological data, such as electroencephalograms (EEG) and heart rate variability (HRV) that algorithms can then process to make these predictions. Electroencephalograms are commonly used tools in neuroscience research which measure electrical activity of the brain with the usage of small metal electrodes attached to the scalp.
LEARN MORE: Electroencephalogram (EEG)
LEARN MORE: Brain activation and heart rate variability as markers of autonomic function under stress
Bioinformatics has the least direct applications of all of these tools, and my thesis does not spend much time on this approach. However, bioinformatics tools can provide solutions “behind the scenes” through the identification of important biomarkers. Through computational tools that translate massive datasets to scientific findings, bioinformatics can identify DNA or protein sequences that correlate with abnormalities in the brain.
LEARN MORE: Deep Learning for Health Informatics
LEARN MORE: Translational bioinformatics and data science for biomarker discovery in mental health: an analytical review
Translational bioinformatics seeks to disseminate biological information from research bench to patient bedside — to improve patient outcomes. In mental health, researchers have identified many biomarkers associated with common anxiety disorders to rare personality disorders. In some cases, protein-based biomarkers have enabled early detection and diagnosis of these conditions.
I think that these methods have substantial potential to bridge the explanatory gap in mental health. Despite this, many issues with implementation exist. A major issue is how modern machine learning research tends to neglect traditional methods of health, such as physiological signals, and relies heavily on human-labeled data to provide results. This can lead to blind spots in cases of rare disease or when new environments, including different cognitive experiences in patients, are present.
Going from bench to bedside is challenge— very few machine learning tools currently exist in clinical healthcare.
Overall, methods described in my thesis have “potential,” but I believe that further research is needed to bring these technologies to bedside with the guarantee it will help more than harm. These fields have high overlap—for example, neural networks are used for modeling sequences that bioinformatics can identify. Through researchers identifying these overlapping traits, it is more likely methods proposed in research can be more than just that.
Current progress and setbacks
I am currently examining numerous computational methods, especially deep learning models, and tracking the most recent developments. One specific research question I have is: “Do computational techniques, especially in machine learning, have the potential to provide better explainability of current treatments in mental health to guide future research?”
“Potential” refers to multiple qualities, including the advantages and use cases of specific tools, particularly machine learning algorithms, developments of particular tools in the past 20 years, and using machine learning metrics to standardize results. I will conclude my thesis with an emphasis on what I find are the most effective methods.
A current limitation I’m facing is the absence of accessible technical tools. It will be hard to come up with organic observations or to “test” metrics out; rather, most of my observations will be from reading existing research. I also do not have access to the high-end equipment typically used by scientists in research of this nature, so my thesis will be limited to a literature review.
Overall, the structure of my paper will delve into problems clinicians and neuroscientists face when diagnosing and treating depression and anxiety, discuss prior methods scientists have used to counter these issues, connect them with newer developments, and conclude on current progress and whether this “potential” for machine learning tools actually exists.
I hope that my research, which is mostly geared towards those outside the computer science realm, provides a clear overview of what techniques in machine learning/AI actually work, and which ones have no evidence for use.
I have really enjoyed this work!
The interplay of theory and practical applications was one of my favorite parts about this experience, and I am finishing up my thesis with a better understanding of how to formulate scientific questions and get those thoughts out on paper and presentation. This is especially important with a subject as complex, and one might argue, niche, as computational psychiatry.
After graduating this year, I plan to continue research related to my thesis, potentially through a research position or graduate school. I have also been conducting research at the Database & Internet Privacy (DIPr) lab at the Maseeh College of Engineering and Computer Science at Portland State, where I’m learning about privacy mechanisms and access control in databases.
While seemingly separate from what I have been working on in my thesis, there is overlap conceptually; database privacy often means patient privacy, and is something computer science researchers have to consider when developing healthcare methodologies.
I am grateful for the support of Dr. Singh and my other mentors at PSU and would have not been compelled to continue a career in research without their support.